Formally verifying the complexity of OCaml programs with CFML -- interlude
- July 30, 2015
- Last updated on 2015/08/03
This small interlude post is not about Coq nor CFML: I present a data structure from Okasaki’s Purely functional data structures, implemented in OCaml.
It comes as a preliminary explanation for an incoming formalization of it in CFML (see next post), including an complexity analysis!
The structure we decided to study is Okasaki’s “binary random access
list”. It is a functional data structure, which features usual list
operations (cons and uncons for adding and
removing an element at the head of the list), but also random access
lookup and update. That is, you can add or
remove an element at the head of the list, but also modify or query the
\(i^{th}\) element of the
structure.
These four operations perform in worst-case \(O(log(n))\) steps, where \(n\) is the number of elements stored in the structure.
Let us see step by step how it is implemented in OCaml. The source code for the complete implementation can be found here.
Type definitions, implicit invariants
A binary random access list is a list of binary trees: we first
define a tree OCaml type.
type 'a tree = Leaf of 'a | Node of int * 'a tree * 'a treeNotice that only the leaves store elements. Nodes contain an integer
corresponding to the number of elements stored (in the leaves) in the
tree, which makes a size function trivial to implement:
let size = function
| Leaf x -> 1
| Node (w, _, _) -> wNow, a binary random access list is a list of either a tree, either nothing. We consequently define an “tree option” type, here dubbed “digit”.
type 'a digit = Zero | One of 'a treeThe name “digit” comes of the similarity between a binary random access list and a list of bits, representing an integer - adding an element at the head being similar to incrementing the integer, etc. We’ll see more of that later.
Finally, we define the type for the whole structure: the binary random access list.
type 'a rlist = 'a digit listA valid binary random access list should satisfy some additional invariants:
Trees are complete trees – a tree of depth \(d\) always has \(2^d\) leaves;
Any
rlistcontains trees of increasing depth starting at some depth \(p\): if the \(i^{th}\) cell (indexing from \(0\)) contains a tree (is of the formOne t), then this tree has depth \(p+i\).A complete binary random access list is a
rlistwith starting depth \(p\) equal to \(0\): its first tree, if present, is only a leaf.
To sum up, a binary random access list is a list, which stores in its \(i^{th}\) cell either nothing, or a complete binary tree of depth \(i\).
As an example, a binary random access list storing the sequence \(1, 2, 3, 4, 5\) can be represented as:
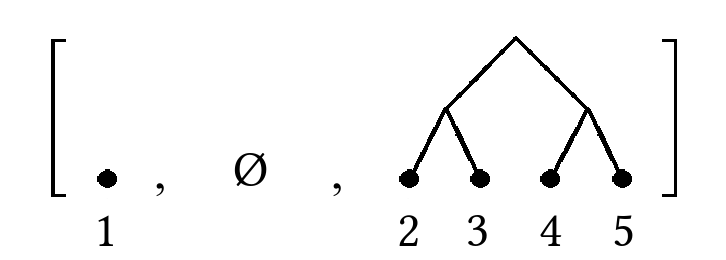
Binary random access lists look like integers in binary
As I mentioned before, a binary random access list is in fact quite similar to an integer represented in binary - i.e. as a list of bits.
Actually, if you erase the trees from the implementation
(type 'a digit = Zero | One of 'a tree becomes
type digit = Zero | One), you obtain an implementation of
integers, represented as a list of bits (least significant bit at the
head of the list); the cons operation being incrementing,
the uncons one decrementing (lookup and
update do not make much sense, though).
How do you increment an integer? You look at the least significant bit; if it’s a zero, you turn it into a one; if it’s a one, you turn it into zero, and recursively continue to increment, starting with the next bit.
“Consing” to a binary random access list is similar, except that we have to handle a bit more information: the elements of the structure, stored in the trees.
Instead of adding \(1\), we add a
tree t (more precisely, a digit One t): if the
first element of the list is Zero, we turn it into
One t. If it’s a One t', we turn it into
Zero, and recursively continue, but with a new tree:
Node (size t + size t', t, t'). This corresponds to the
link operation, which combines two trees of depth \(d\) into one of depth \(d+1\).
let link t1 t2 =
Node (size t1 + size t2, t1, t2)The OCaml implementation follows:
let rec cons_tree t = function
| [] -> [One t]
| Zero :: ts -> One t :: ts
| One t' :: ts -> Zero :: cons_tree (link t t') ts
let cons x ts =
cons_tree (Leaf x) tsThe uncons operations follows the same idea: it’s just
like decrementing, except that you also have to invert the
link operation to obtain trees of smaller depth.
let rec uncons_tree = function
| [] -> raise Empty
| [One t] -> (t, [])
| One t :: ts -> (t, Zero :: ts)
| Zero :: ts ->
match uncons_tree ts with
| Node (_, t1, t2), ts' -> (t1, One t2 :: ts')
| _ -> assert false
let head ts =
match uncons_tree ts with
| (Leaf x, _) -> x
| _ -> assert false
let tail ts =
let (_,ts') = uncons_tree ts in ts'Unconsing a rlist of starting depth \(p\) always returns a tree of depth \(p\) (or fails if the list is empty). In
particular, as the binary access list manipulated by the user always
starts with depth \(0\), we can assume
in the implementation of head that the unconsed tree is a
leaf.
Random access
Random access lookup and update are quite easy to implement.
The idea is to walk through the list; faced with a
Node (w, l, r) tree, we know how much elements it contains:
it is exactly w. Knowing the index \(i\) of the element we want to visit, we can
compare it to w to know whether we should explore this tree
(if \(i < w\)), or look for the
element \(i - w\) in the rest of the
list.
let rec lookup i = function
| [] -> raise (Invalid_argument "lookup")
| Zero :: ts -> lookup i ts
| One t :: ts ->
if i < size t
then lookup_tree i t
else lookup (i - size t) tsIf we have to walk through the tree, we can also do this without performing an exhaustive exploration: by comparing the index to half the size of the tree, we can decide whether we should explore the left or right subtree.
let rec lookup_tree i = function
| Leaf x -> if i = 0 then x else raise (Invalid_argument "lookup")
| Node (w, t1, t2) ->
if i < w/2
then lookup_tree i t1
else lookup_tree (i - w/2) t2The update function works in a similar fashion.
let rec update_tree i y = function
| Leaf x -> if i = 0 then Leaf y else raise (Invalid_argument "update")
| Node (w, t1, t2) ->
if i < w/2
then Node (w, update_tree i y t1, t2)
else Node (w, t1, update_tree (i - w/2) y t2)
let rec update i y = function
| [] -> raise (Invalid_argument "update")
| Zero :: ts -> Zero :: update i y ts
| One t :: ts ->
if i < size t
then One (update_tree i y t) :: ts
else One t :: update (i - size t) y tsNext time
Final post incoming, where I present a formalization of this exact OCaml implementation, using CFML and the time credits-related functions I presented in the first post. Stay tuned!