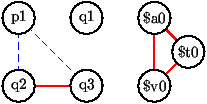
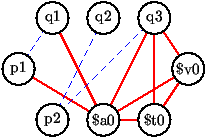
- Le graphe d'interférence comporte
les trois registres et
quatre autres noeuds
p2,q1,q2.q3. Il comporte un seul arc (q2,q3) d'interférence en plus du sous-graphe plein des interférences entre registres (que l'on pourrait omettre).
- Les arcs d'attirance qui ne sont pas demandés.